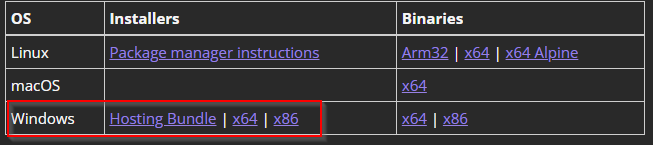
X.509 is a standard format for public key certificates, digital documents that securely associate cryptographic key pairs with identities such as websites, individuals, or organizations.
First introduced in 1988 alongside the X.500 standards for electronic directory services, X.509 has been adapted for internet use by the IETF’s Public-Key Infrastructure (X.509) (PKIX) working group
Common applications of X.509 certificates include:
- SSL/TLS and HTTPS for authenticated and encrypted web browsing
- Signed and encrypted email via the S/MIME protocol
- Code signing
- Document signing
- Client authentication
- Government-issued electronic ID
For more info, read below;