If you are building a Single Page Application / JavaScript Web application using Visual Studio, you’ve probably already run into the overlap between tooling that surrounds npm and the tooling within Visual Studio.
One of these tasks is preventing Visual Studio from being responsible for building TypeScript and allowing your tooling (i.e. Webpack, Gulp, Grunt) to be in charge instead. The idea here is that your tooling has been configured to lint, minify, build, concat, bundle, copy, whatever all of your project files exactly as you desire. At this point you don’t really need MSBuild involved in transpiling your JavaScript to TypeScript as it would be redundant and often times problematic. To prevent Visual Studio from doing any compilation of TypeScript preform the following steps:
Ensure a tsconfig file is added to the project and configured correctly
TypeScript and any build process you are using will work together based on the configuration in tsconfig.json. This file can be hand-rolled from scratch, or may have been generated for your project from a process like ng new and the Angular CLI. You can also generate a default tsconfig file (recommended approach as opposed to creating from scratch) using the following command: tsc --init
This will generate a default configuration file for TypeScript compilation. Your web-client’s code build process will need to point to this file and using it as a driver for the TypeScript compilation behavior.
2. Modify the .csproj project file to prevent TypeScript from compiling
Within Visual Studio, right-click your project and select the option to edit the .csproj file. These options are in a XML format and the following needs to be added: <PropertyGroup> <TypeScriptCompileBlocked>true</TypeScriptCompileBlocked> </PropertyGroup> If you still want MSBuild to handle your TypeScript compilation there are several options that will change the behavior:
On a technical note, you can think of it as Bootstrap implementation of USWDS though it’s not Bootstrap. It comes with its own CSS classes, themes, icons and JavaScript modules.
Installation instruction is straight forward for Web development tools that doesn’t require TypeScript to implement client side behavior, for example ASP.NET Core, PHP etc.
My challenge was to implement this in Angular v18.0. While searching for Typescript modules, I found Angular package in their documentation;
Installation instructions are very simple. Run this;
npm install @gsa-sam/ngx-uswds
As of this writing this package targets Angular 17 and you might get an error installing this. Run this command to force it to install;
npm install @gsa-sam/ngx-uswds --force
You will see a folder under node_modules in your project.
Basic installation is done;
1 - npm install --save uswds@latest
2 - add "node_modules/uswds/dist/css/uswds.min.css" to the "styles"
section of angular.json
3 - add "node_modules/uswds/dist/js/uswds.min.js" to the "scripts"
section of angular.json
How we are going to use it? In my case, I need to bring in individual component, for example a modal dialog box.
Create a component in your application;
ng g c my-modal
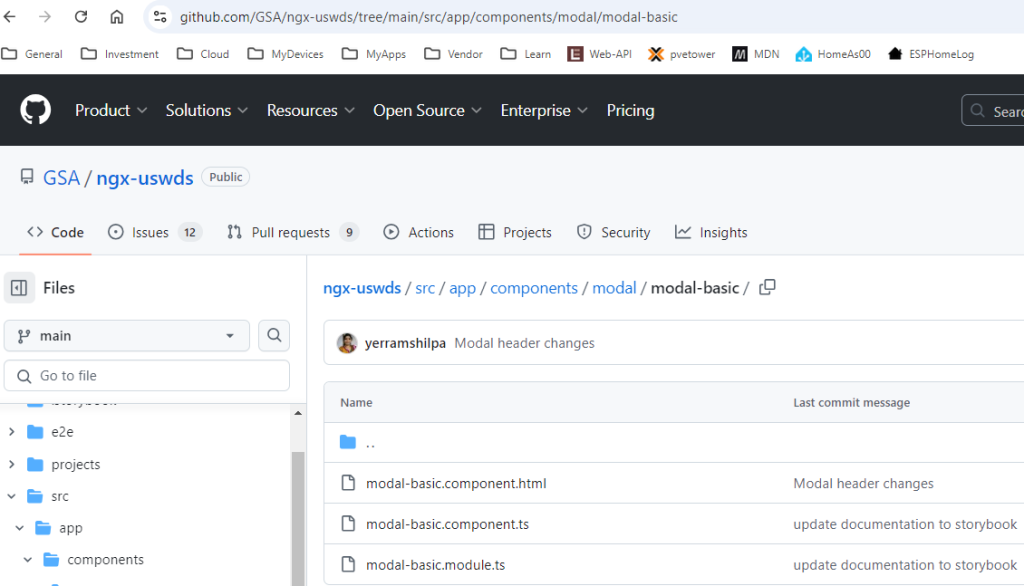
Open my-modal component. Open modal-basic.component.ts file from their github repo. see picture below;
Paste their code in your component and template file. You are good to go.
Their is another option that seems to be promising on GSA front;
Favicon icon also known as a shortcut icon, website icon, tab icon, URL icon, or bookmark icon, is a file containing a small icon. associated with a particular website or web page. A web designer can create such an icon and upload it to a website or a web page. Its associated with a website at address bar. In angular it is stored with a default name i.e favicon.ico which is angular logo, we can change it in simple steps as below. So, let’s get started, Step 1: copy your logo in src folder Step 2: Navigate to src folder and remove the favicon.ico file. Step 3: copy new png favicon inside src folder. Step 4: Open the index.html file and change the favicon file name (with the newly added icon name).
Step 5: Inside the angular.json file change name of the favicon in assets array. “assets”: [ “src/favicon.png”, “src/assets” ],
That’s it, In these five steps we can easily replace favicon icon in Angular.