This is a simple comparison based off of Hand-coded (using SqlDataReader) benchmark of select mapping over 500 iteration – POCO serialization, which is 47ms.

This is a simple comparison based off of Hand-coded (using SqlDataReader) benchmark of select mapping over 500 iteration – POCO serialization, which is 47ms.
Lets take a look at two queries using CURSORS, the first one will use the FORWARD_ONLY type cursor, and the second will use the FAST_FORWARD type cursor. These two types sound very similar, but perform quite differently.
DECLARE @firstName as NVARCHAR(50);
DECLARE @middleName as NVARCHAR(50);
DECLARE @lastName as NVARCHAR(50);
DECLARE @phone as NVARCHAR(50);
DECLARE @PeoplePhoneCursor as CURSOR;
SET @PeoplePhoneCursor = CURSOR FORWARD_ONLY FOR
SELECT TOP 10 FirstName, MiddleName, LastName, PhoneNumber
FROM person.Person p
INNER JOIN person.personphone pp on p.BusinessEntityID = pp.BusinessEntityID;
OPEN @PeoplePhoneCursor;
FETCH NEXT FROM @PeoplePhoneCursor INTO @firstName, @middleName, @lastName, @phone;
WHILE @@FETCH_STATUS = 0
BEGIN
PRINT ISNULL(@firstName, '') + ' ' +
ISNULL(@middleName, '') + ' ' +
ISNULL(@lastName, '') +
' Phone: ' + ISNULL(@phone, '') ;
FETCH NEXT FROM @PeoplePhoneCursor INTO @firstName, @middleName, @lastName, @phone;
END
CLOSE @PeoplePhoneCursor;
DEALLOCATE @PeoplePhoneCursor;Now for the FAST_FORWARD CURSOR example. Notice only one line has changed, that’s the line that says “SET @PeoplePhoneCursor = CURSOR FAST_FORWARD FOR”.
DECLARE @firstName as NVARCHAR(50);
DECLARE @middleName as NVARCHAR(50);
DECLARE @lastName as NVARCHAR(50);
DECLARE @phone as NVARCHAR(50);
DECLARE @PeoplePhoneCursor as CURSOR;
-- HERE IS WHERE WE SET THE CURSOR TO BE FAST_FORWARD
SET @PeoplePhoneCursor = CURSOR FAST_FORWARD FOR
SELECT TOP 10 FirstName, MiddleName, LastName, PhoneNumber
FROM person.Person p
INNER JOIN person.personphone pp on p.BusinessEntityID = pp.BusinessEntityID;
OPEN @PeoplePhoneCursor;
FETCH NEXT FROM @PeoplePhoneCursor INTO @firstName, @middleName, @lastName, @phone;
WHILE @@FETCH_STATUS = 0
BEGIN
PRINT ISNULL(@firstName, '') + ' ' +
ISNULL(@middleName, '') + ' ' +
ISNULL(@lastName, '') +
' Phone: ' + ISNULL(@phone, '') ;
FETCH NEXT FROM @PeoplePhoneCursor INTO @firstName, @middleName, @lastName, @phone;
END
CLOSE @PeoplePhoneCursor;
DEALLOCATE @PeoplePhoneCursor;The FORWARD_ONLY CURSOR takes 4 times the time as the FAST FORWARD CURSOR, and the number continues to widen as the number of times the cursor loops is executed.
FAST FORWARD CURSORS are usually the fastest option with SQL Server. There may be cases where another option may work better, but the FAST FORWARD CURSOR is a good place to start if you must use a CURSOR.
The best practice is to avoid cursor but sometime they are inevitable. The alternatives could be temp tables, while loops etc.
Recently I had a problem where i need to search for;
SQL Server default behavior is to do case insensitive search. so if run a query like this;
IF OBJECT_ID('tempdb..#FooTable') IS NOT NULL DROP TABLE #FooTable
SELECT x.*
INTO #FooTable
FROM
(
SELECT 1 AS Id, 'Foo' AS UserName
UNION ALL
SELECT 2 As Id, 'foo' AS UserName
) x
I will get two records back.
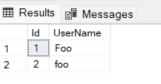
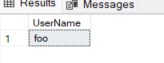
To do a case sensitive search, do this;
SELECT UserName
FROM #FooTable
WHERE 1=1
AND UserName = 'foo' COLLATE SQL_Latin1_General_CP1_CS_AS
Result would be;
For join operations, let’s create another table;
--Now add a second table, say salary
IF OBJECT_ID('tempdb..#FooSalaryTable') IS NOT NULL DROP TABLE #FooSalaryTable
SELECT x.*
INTO #FooSalaryTable
FROM
(
SELECT 1 AS Id, 'Foo' AS FooId, 4000 AS UserSalary
UNION ALL
SELECT 2 As Id, 'foo' As FoodId, 6000 AS UserSalary
) x
SELECT * FROM #FooSalaryTable
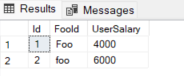
This is join query;
--example with join
SELECT
x.UserName, y.UserSalary
FROM #FooTable x
JOIN #FooSalaryTable y on x.UserName = y.FooId COLLATE SQL_Latin1_General_CP1_CS_AS
WHERE 1=1
AND x.UserName = 'foo' COLLATE SQL_Latin1_General_CP1_CS_ASand results;
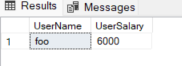
For more info, follow these articles;
https://www.mssqltips.com/sqlservertip/1032/case-sensitive-search-on-a-case-insensitive-sql-server/
https://stackoverflow.com/questions/17172175/add-column-to-temp-table-invalid-column-name-decimal
There are situations where you might receive this error message “Transaction count after EXECUTE indicates a mismatching number of BEGIN and COMMIT statements. Previous count = 0, current count = 1.”. Even when using a TRY CATCH block in the stored procedure and a ROLLBACK in the catch block, this error still occurs. One reason this is not captured is because fatal errors are not caught and the transaction remains open. In this tip we will look at how you can handle this issue.
Refer to this article for solution;
Recently i had to search for a specific column in database. My assumption was that the column name would be same as the column name in parent table. For example Person table PersonID column would be name same in all reference tables.
USE MyDatabase
--find all columns with a specific name in database
SELECT OBJECT_SCHEMA_NAME(ac.object_id) SchemaName,
OBJECT_NAME(ac.object_id) TableName,
ac.name as ColumnName, tp.name DataType
FROM sys.all_columns ac
INNER JOIN sys.types tp ON tp.user_type_id = ac.user_type_id
WHERE ac.name = 'YourColumnName'
GO
Resources
Read more here…