I had an Excel file with a single column of 6000 characters (huge text). I used ACE drive and SSIS Build-in Excel connection manager.
The package worked initially with huge text configuration. I removed all the content from column and added three characters for testing. The package started failing.
Status Failed-SSIS Error Code DTS_E_OLEDBERROR. An OLE DB error has occurred. Error code: 0x80040E21. An OLE DB record is available. Source: "Microsoft Access Database Engine" Hresult: 0x80040E21 Description: "Multiple-step OLE DB operation generated errors. Check each OLE DB status value, if available. No work was done.".
Status Failed-Failed to retrieve long data for column "SQLStatement".
Status Failed-There was an error with Excel - Get worksheet detail data.Outputs[Excel Source Output] on Excel - Get worksheet detail data. The column status returned was: "DBSTATUS_UNAVAILABLE".
Status Failed-SSIS Error Code DTS_E_INDUCEDTRANSFORMFAILUREONERROR. The "Excel - Get worksheet detail data.Outputs[Excel Source Output]" failed because error code 0xC0209071 occurred, and the error row disposition on "Excel - Get worksheet detail data" specifies failure on error. An error occurred on the specified object of the specified component. There may be error messages posted before this with more information about the failure.
Why?
For some strange reasons, SSIS Built-in Excel connection manager doesn’t respect the variation of content. If the content size is less than 100 and we have configured as Unicode text stream [DT_NTEXT], it will blow up.
The work around is use Script Component and use it as source.
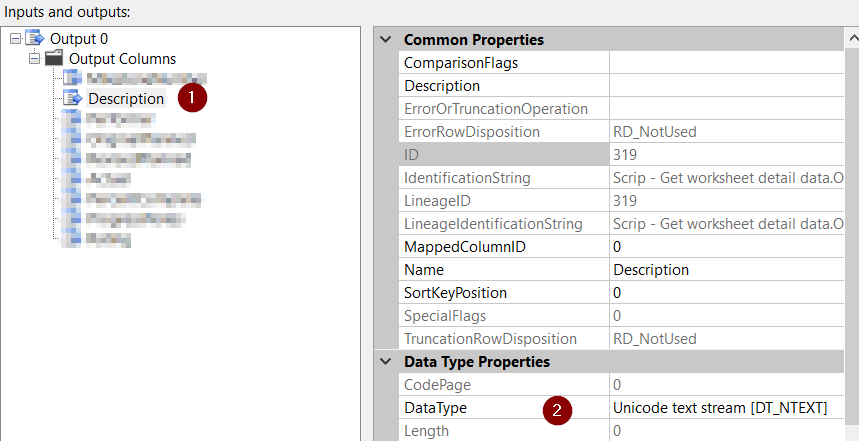
Add a column to Output column of Output buffer;
Click on Edit Script and add paste following code;
public class ScriptMain : UserComponent
{
DataSet excelDataSet;
public override void PreExecute()
{
base.PreExecute();
string connString = $"Provider=Microsoft.ACE.OLEDB.12.0;Data Source=C:\myExcelFile.xlsx;Extended Properties=Excel 12.0";
//Connect Excel sheet with OLEDB using connection string
using (OleDbConnection conn = new OleDbConnection(connString))
{
conn.Open();
OleDbDataAdapter objDA = new OleDbDataAdapter("SELECT * FROM [Portfolio$A10:I] WHERE Performer IS NOT NULL", conn);
excelDataSet = new DataSet();
objDA.Fill(excelDataSet);
}
public override void CreateNewOutputRows()
{
DataTable tbl = excelDataSet.Tables[0];
foreach (DataRow row in tbl.Rows)
{
Output0Buffer.AddRow(); Output0Buffer.Description.AddBlobData(Encoding.Unicode.GetBytes(row[0].ToString()));
}
}
Open your Excel file and add a lot of data, for example 6000 characters, in Description column. The package will run successfully.
Again open your Excel file and add merely 3 characters in Description column. The package will run successfully again.
The success reason, We are not using Built-in Excel connection manager and are not affected by the weird behavior.
These solutions are from Microsoft Social Site;
This one seems to be a workable solution. These are pre-requisite for this approach;
ACE drive installation
Running following commands. Make sure you know the risk because these are related to security configuration of your database server.
sp_configure 'show advanced options', 1;
GO
RECONFIGURE;
GO
sp_configure 'Ad Hoc Distributed Queries', 1;
GO
RECONFIGURE;
GO
USE [master]
GO
--if using 32 bit office
EXEC master.dbo.sp_MSset_oledb_prop N'Microsoft.ACE.OLEDB.12.0', N'AllowInProcess', 1
--if using 64 bit office
EXEC master.dbo.sp_MSset_oledb_prop N'Microsoft.ACE.OLEDB.16.0', N'AllowInProcess', 1
GO
--if using 32 bit office
EXEC master.dbo.sp_MSset_oledb_prop N'Microsoft.ACE.OLEDB.12.0', N'DynamicParameters', 1
--if using 64 bit office
EXEC master.dbo.sp_MSset_oledb_prop N'Microsoft.ACE.OLEDB.16.0', N'DynamicParameters', 1
GO
We can package following stored procedure and call it from SSIS.
DECLARE @tbl TABLE (
col1 VARCHAR(50)
, col2 VARCHAR(50)
, col3 VARCHAR(50)
, col4 VARCHAR(MAX)
);
INSERT INTO @tbl
SELECT *
FROM OPENROWSET('Microsoft.ACE.OLEDB.12.0',
'Excel 12.0 Xml; HDR=NO;
Database=c:\Users\Yitzhak\Documents\dada.xlsx',
[data$]);
-- just to test
SELECT * FROM @tbl;
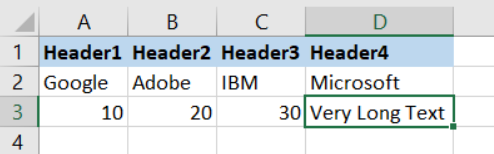
Output
-------
col1 col2 col3 col4
Header1 Header2 Header3 Header4
Google Adobe IBM Microsoft
10 20 30 Very Long Text
These are alternative approaches just for reference;
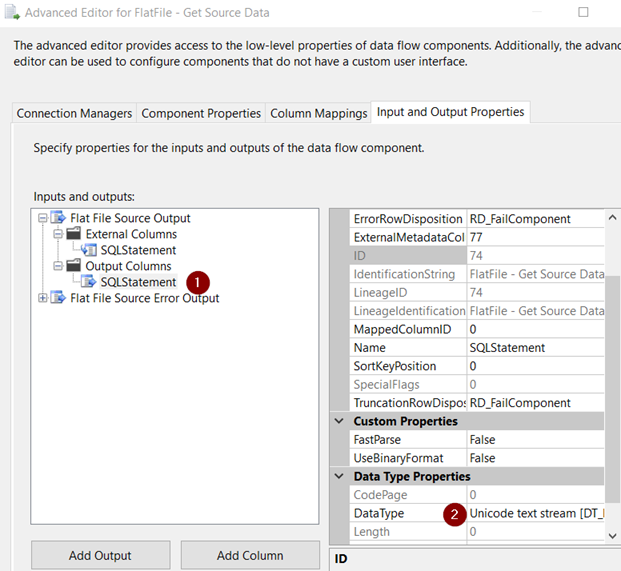
Metadata at the Excel Source component’s output (checked using Advanced Editor): DT_NTEXT
Derived Column component between source and destination to cast to non-unicode from unicode using (DT_TEXT,1252)
Metadata at the OLE DB Destination component’s input (checked using Advanced Editor): DT_TEXT
Target Column data type: VARCHAR(MAX)
Another approach
The “IMEX=1” extended property for OLE DB Excel connection string is used when there are mixed data types in one column. In this case, you need to change the value of the TypeGuessRows registry key so that Excel driver scans more than 8 rows (by default) to find a value that is longer than 4000 characters. If the registry key is updated successfully, the data type of the external column should be DT_NTEXT, and the data type of the output column will default to DT_NTEXT other than DT_WSTR automatically. So, I am afraid that you have not modified the registry key successfully.
If the source Excel file is .xls file, the provider used will be Microsoft JET OLE DB 4.0. In this case, we need to modify the following registry key from 8 to 0: HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Jet\4.0\Engines\Excel\TypeGuessRows
If the source Excel file is .xlsx file, the provider used will be Microsoft ACE OLE DB 12.0. In this case, we need to modify the proper registry key according to the Office Excel version:
if above will not solve your problem, then the best way to do is:
Suppose you have a column named ‘ColumnX‘ with more than 4000 characters. Then, Load your excel data in a temp table with splitting of ColumnX into two derived columns. I mean to say, split the data of ColumnX into two parts and store it into two columns e.g.
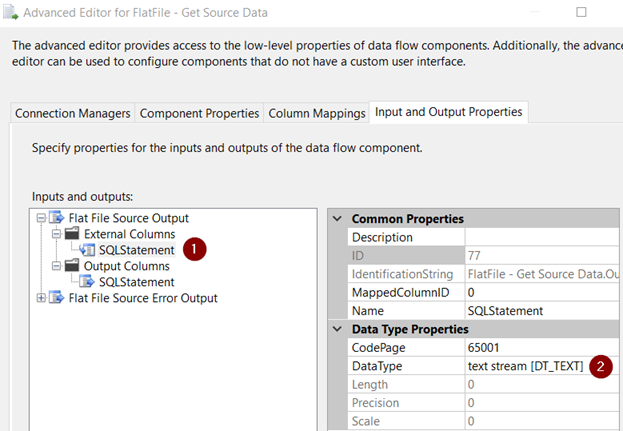
To import large text including special and foreign characters using Flat File follow this;
External Column = Text_Stream (DT_TEXT)
Output Column = Unicode Text Stream (DT_NTEXT)
This can handle up to 11000 characters. I think it’s more than sufficient. Make sure your SQL Database has NVARCHAR(MAX) column data type.
This will work if the column has 11000 characters or 1 character. It wouldn’t break the way Excel BLOB columns break. In Excel if the source column is configured as DT_NEXT and data is 1 character, the process blows up.
By default, SQL Server services run under these accounts;
Sometimes administrator might have changed these service accounts to window accounts for management reasons. To get them back to default accounts, right click on service and change them to NT Service\[Account Name] where [Account Name] is above listed account without any password. Windows know how to setup the password.
We would like to create a windows proxy account so that we can use it inside SQL server. The intent is to use this account to read/write from windows file system.
I am using my local laptop for this demo but you can use a domain account. The only difference would be to change [ComputerName]\[AccountName] to [DomainName[\[AccountName].
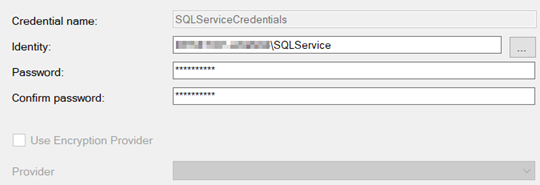
You might have received this user from your domain administrator. If not then create a Windows user “SQLService” on your local computer and make him member of “Users” group only.
Next Open SIMS -> Security -> Login -> New Login.
Server Role -> public.
User Mapping -> msdb -> db_ssisoperator, public
User Mapping -> SSISDB -> ssis admin, public
Next Security -> Credentials -> New Credentials
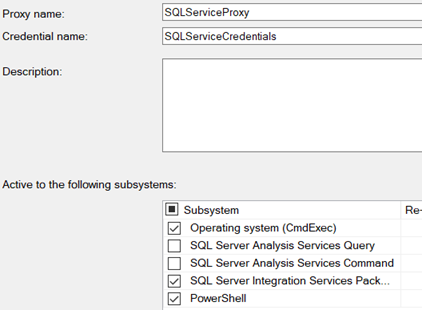
Next SQL Server Agent -> Proxies -> SSIS Package Execution -> New Proxy
I have selected “Operating system (CmdExec) and “PowerShell” additional subsystems. You might not need these.
Under Principals, Select your windows service account;
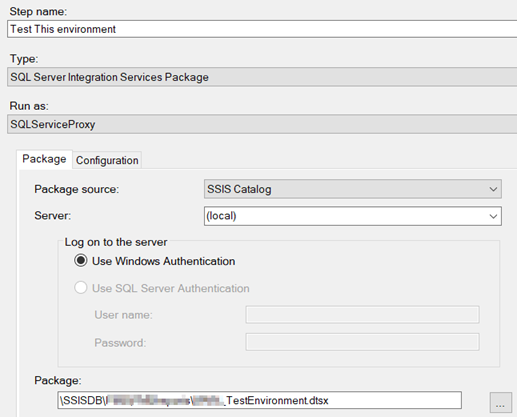
Deploy your integration service packages. You will be able to see them under SSISDB->[Folder Name]\[Project Name]. Run your package. It will successeded because you are running them under your security context;
Create a job with a job step in SQL Server Agent. Make sure to change the context “Run as: SQLServiceProxy”;
When you run the job, it will fail. The reason, its running under the context of SQLService account. Connections within integration services are made with integrated security not SQL server.
Since we will be using SQL Login so I am going to change SSIS connection string in environment variables.
Now when you run the package, it will succeed.
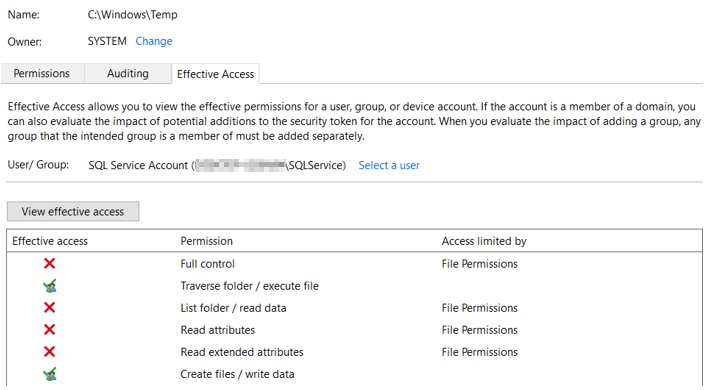
Its time to check file system access. Open c:\windows\temp folder and see effective permission of SQLService account;
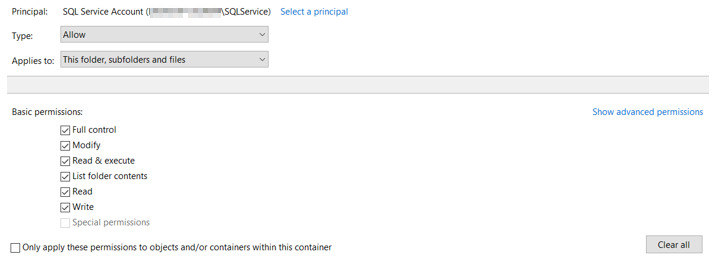
Grant full permission on this folder;
Script tasks require access to this folder for .NET framework and other temporary operations.
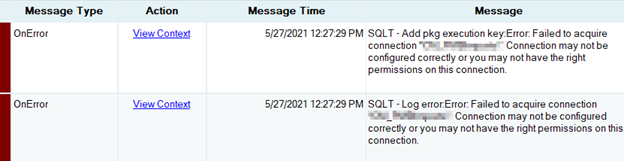
Still if you get this error;
The cause, SQLService windows account is not part of “Distributed COM Users” group on the machine where SSIS is installed. Add SQLService account to this windows group. You can read more about this here;
If the package fails again on server and you see this error in windows event viewer;
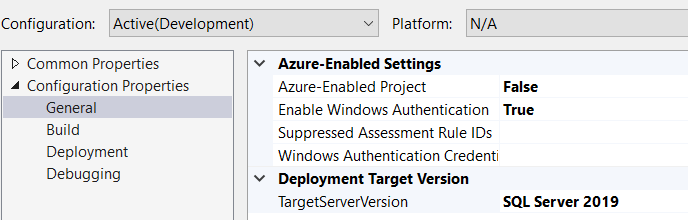
Make sure your SSIS project is targeting correct SQL Server Version. Right Click on your SSIS project -> Properties;
Deploy your project.
For SQL Server 2019 you need to set “False” for Azure-Enabled Project. As of this writing Azure-Enabled Project works with SQL Server 2017 only.
Run the package and everything should be Green now (hopefully :). We are done.
The above setup will work if we are reading/writing files in a domain controller environment or on a single server.
Setting up Azure Storage for reading/writing files
Service accounts are normally not interactive accounts. If we are using Azure Storage for reading/writing files with SAS then we would need to save Azure credentials in Credential Manager. To get to Credential Manager we need to login on server with our service account that will make it interactive.
Follow these steps;
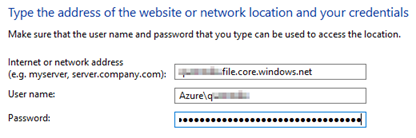
Login to server with [servername]\SQLService account. If you are doing RDP, make sure this account is member of “Remote Desktop users” user’s group. Search for credential manager.
Remove this account from “Remote Desktop users”. Run agent, still fails.
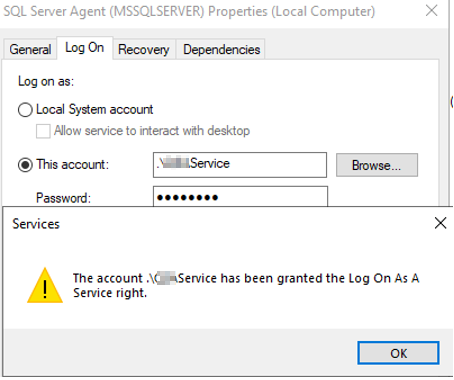
Try to Run SQL Server Agent under windows service account;
This time this started working. This is an alternative approach. We are using service account to run SQL Server agent. If this is the case then we don’t need to setup credentials and proxy accounts in SQL Server.
What happened behind the scene. Windows service account is granted “Log on as service permission” by windows. We can verify this following “Enable service log on through a local group policy” section below.
If we want to revert to “NT Service\SqlServerAgent” as service account, simply change your service account from windows service to SqlServerAgent and it would still work.
Follow this to allow an account “Login as service” permission manually if required;
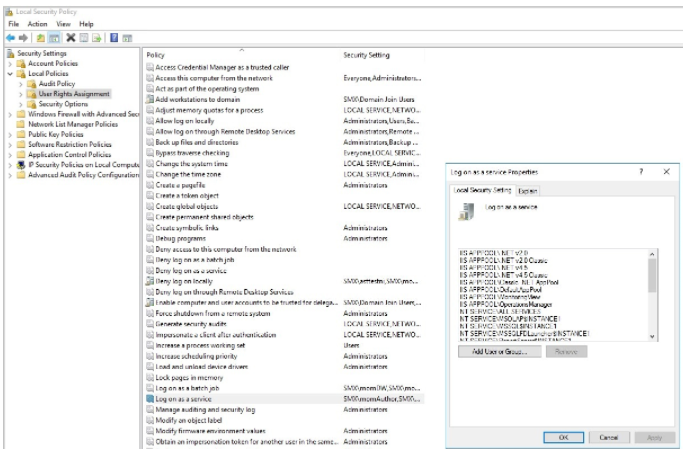
Enable service log on through a local group policy
Follow these steps:
Sign in with administrator privileges to the computer from which you want to provide Log on as Service permission to accounts.
Go to Administrative Tools, click Local Security Policy.
Expand Local Policy, click User Rights Assignment. In the right pane, right-click Log on as a service and select Properties.
Click Add User or Group option to add the new user.
In the Select Users or Groups dialogue, find the user you wish to add and click OK.
Click OK in the Log on as a service Properties to save the changes.