LINQ pronounced as “Link” is a .NET component that enables the processing of the native queries directly into C# and VB.NET languages. LINQ has Distinct() function which provides the unique list of values from a single data source.
Example Class – LINQ Distinct by Property or Field Using Distinct function
The Distinct() method is used to remove the duplicate values from the list and gives the unique values. Let us consider the example in which you need to have unique values from Book List, and you have the following model:
public class Book
{
public int BookID { get; set; }
public string Title { get; set; }
public string Author { get; set; }
}
List of dummy data of the books. In real word scenario, the list is could be from live database or any other data source.
public List GetBooks()
{
List books = new List();
books.Add(new Book { BookID = 1, Title = "Book Title 1", Author = "Author 1" });
books.Add(new Book { BookID = 2, Title = " Book Title 2", Author = "Author 2" });
books.Add(new Book { BookID = 3, Title = " Book Title 3", Author = "Author 1" });
books.Add(new Book { BookID = 4, Title = " Book Title 4", Author = "Author 2" });
books.Add(new Book { BookID = 5, Title = " Book Title 5", Author = "Author 8" });
books.Add(new Book { BookID = 6, Title = " Book Title 4", Author = "Author 2" });
books.Add(new Book { BookID = 7, Title = " Book Title 6", Author = "Author 4" });
books.Add(new Book { BookID = 8, Title = " Book Title 8", Author = "Author 2" });
books.Add(new Book { BookID = 9, Title = " Book Title 3", Author = "Author 3" });
books.Add(new Book { BookID = 10, Title = " Book Title 5", Author = "Author 1" });
return books;
}
LINQ Distinct() using Property
The Distinct() function in LINQ can be applied by the properties. You can make groups and get the first object from each group or you can use DistinctBy function to achieve the required result.
LINQ DistinctBy() On a Property
DistinctBy() apply on a specified property to get unique values from a list of objects. If you need a distinct list based on one or more properties, you can use the following code:
List bookList = GetBooks().DistinctBy(book => new { book.BookID, book.Title });
Using GroupBy and Select on a Property
By taking the above sample data, you can get the distinct author list by using the following code, as it will group the similar author named books first, and then select the first of every group in list.
List bookList = GetBooks().GroupBy(book => book.Author).Select(x => x.First()) .ToList();
LINQ Distinct By – Field
The Distinct() function in LINQ can be applied on the fields of tables also. This will group the similar data of the given field and return the unique list by selecting the first or default of the group depending on the requirement.
yourTable.GroupBy(x => x.TableFieldColumn).Select(x => x.FirstOrDefault());
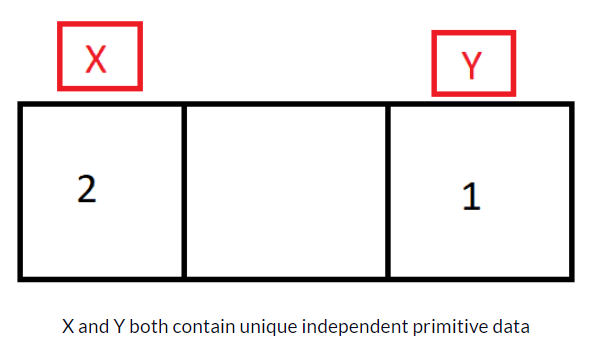
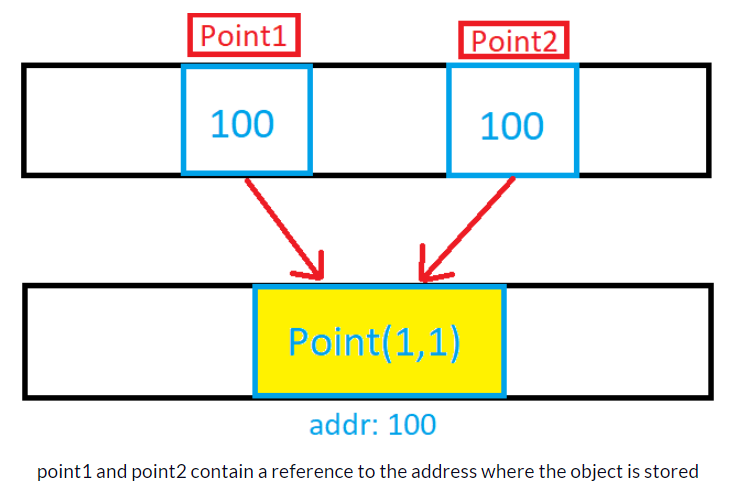
When you use reference type object, LINQ will treat the values as unique even the property values are same. To overcome this situation, you can use either of the following ways to have distinct values:
LINQ Group By and Select Operators
In this method, GroupBy function is used to group the list which can either be a static list or a dynamic list. The Select operator is used to fetch the results from a list or a grouped list.
In this example, grouping is done by using the groupby operator to group Authors and Title and then Select is used to get the first result of a grouped list.
using System;
using System.Text;
using System.Linq;
namespace MyFirstApp{
public class LINQProgram {
public static void Main(String[] args) {
List bookList = GetBooks()
.GroupBy(book => new { book.Author, book.Title })
.Select(book => book.FirstOrDefault());
}
}
}
Distinct with IEqualityComparer
You can give an instance of IEqualityComparer to an overloaded method of the Distinct method. For that, you need to create a new class “BookComparer” that must be implementing the IEqualityComparer to overload it.
using System;
using System.Text;
using System.Linq;
namespace MyFirstApp{
public class BookComparer : IEqualityComparer // Implements interface
{
public bool Equals(Book x, Book y) {
if (Object.ReferenceEquals(x, y))
return true;
if (Object.ReferenceEquals(x, null) || Object.ReferenceEquals(y, null))
return false;
return x.Author == y.Author && x.Title == y.Title;
}
public int GetHashCode(Book book) {
if (Object.ReferenceEquals(book, null))
return 0;
int hashBookName = book.Author == null ? 0 : book.Author.GetHashCode();
int hashBookCode = book.Title == null ? 0 : book.Title.GetHashCode();
return hashBookName ^ hashBookCode;
}
}
public class LINQProgram {
public static void Main(String[] args) {
List bookList = GetBooks()
.Distinct(new BookComparer());
}
}
}
Using Select and Distinct operators
You can use the Select and Distinct functions to get rid of the repeated values from a list of objects. In the following example, select and distinct operators are used to get the unique values from Books list.
using System;
using System.Text;
using System.Linq;
namespace MyFirstApp{
public class LINQProgram {
public static void Main(String[] args) {
List bookList = GetBooks()
.Select(book => new { book.Author, book.Title })
.Distinct();
}
}
}
LINQ Distinct by Field
If you want to achieve the distinct values for a specific field in the list, you can use the following two methods:
1. Using GroupBy and Select functions
In this approach, you need to use two LINQ functions i.e., GroupBy and Select to get the list of unique field values. You can use the following code to have groupby and select in one query.
using System;
using System.Text;
using System.Linq;
namespace MyFirstApp{
public class LINQProgram {
public static void Main(String[] args) {
List bookList = GetBooks()
.GroupBy(o => o.Author)
.Select(o => o.FirstOrDefault());
}
}
}
2. Using Select and Distinct functions
In the second approach, you need to use two LINQ functions i.e. Select and Distinct, to achieve the list of unique field values.
using System;
using System.Text;
using System.Linq;
namespace MyFirstApp{
public class LINQProgram {
public static void Main(String[] args) {
List bookList = GetBooks()
.Select(o => new { Author = o.Author } )
.Distinct();
}
}
}
Sources
https://stackoverflow.com/questions/19548043/select-all-distinct-values-in-a-column-using-linq
https://learn.microsoft.com/en-us/dotnet/api/system.linq.enumerable.distinct?view=net-7.0