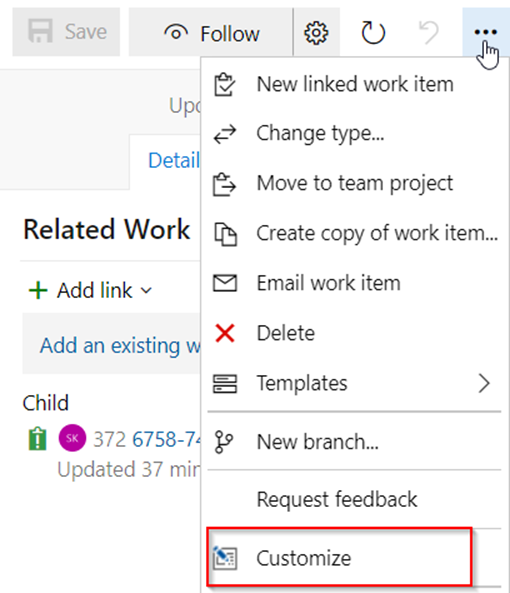
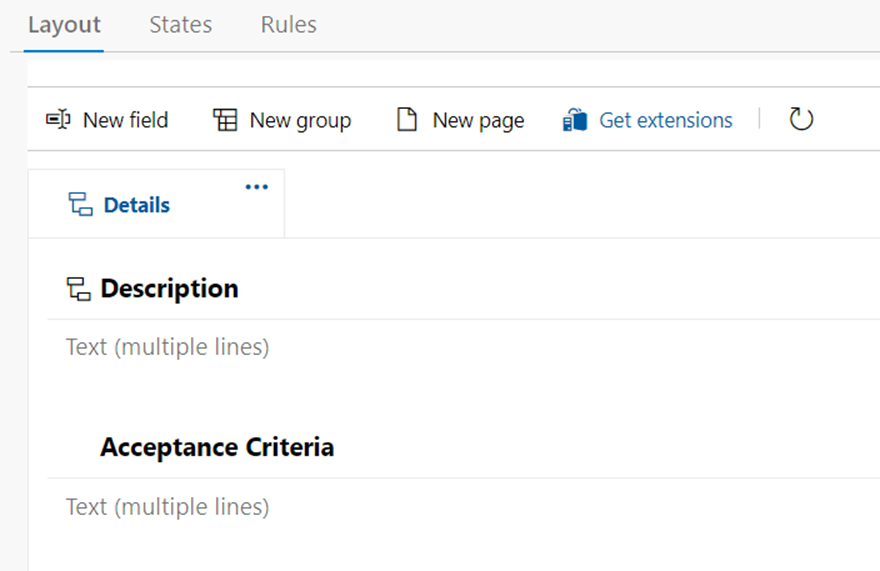
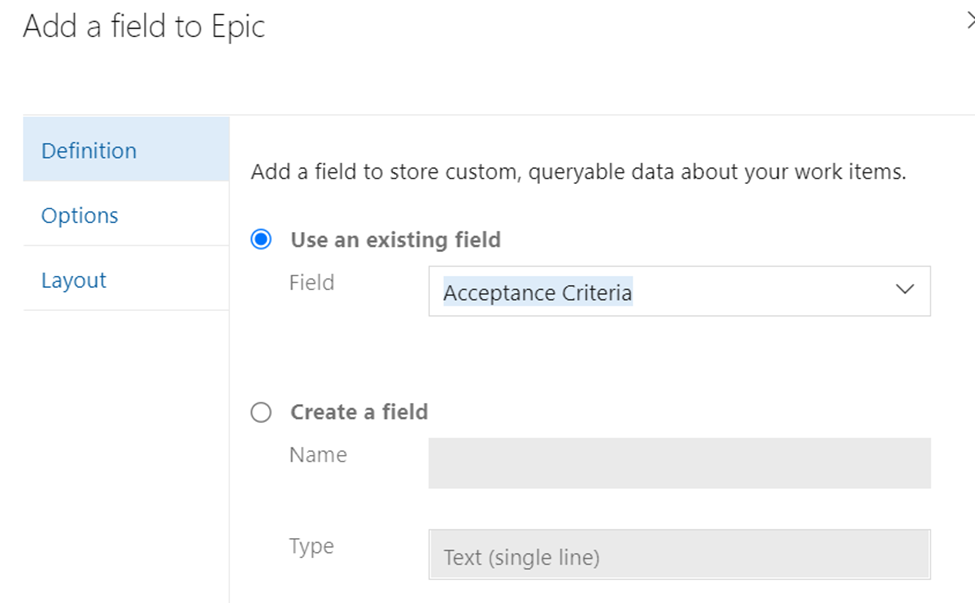
Lets take a look at two queries using CURSORS, the first one will use the FORWARD_ONLY type cursor, and the second will use the FAST_FORWARD type cursor. These two types sound very similar, but perform quite differently.
DECLARE @firstName as NVARCHAR(50);
DECLARE @middleName as NVARCHAR(50);
DECLARE @lastName as NVARCHAR(50);
DECLARE @phone as NVARCHAR(50);
DECLARE @PeoplePhoneCursor as CURSOR;
SET @PeoplePhoneCursor = CURSOR FORWARD_ONLY FOR
SELECT TOP 10 FirstName, MiddleName, LastName, PhoneNumber
FROM person.Person p
INNER JOIN person.personphone pp on p.BusinessEntityID = pp.BusinessEntityID;
OPEN @PeoplePhoneCursor;
FETCH NEXT FROM @PeoplePhoneCursor INTO @firstName, @middleName, @lastName, @phone;
WHILE @@FETCH_STATUS = 0
BEGIN
PRINT ISNULL(@firstName, '') + ' ' +
ISNULL(@middleName, '') + ' ' +
ISNULL(@lastName, '') +
' Phone: ' + ISNULL(@phone, '') ;
FETCH NEXT FROM @PeoplePhoneCursor INTO @firstName, @middleName, @lastName, @phone;
END
CLOSE @PeoplePhoneCursor;
DEALLOCATE @PeoplePhoneCursor;Now for the FAST_FORWARD CURSOR example. Notice only one line has changed, that’s the line that says “SET @PeoplePhoneCursor = CURSOR FAST_FORWARD FOR”.
DECLARE @firstName as NVARCHAR(50);
DECLARE @middleName as NVARCHAR(50);
DECLARE @lastName as NVARCHAR(50);
DECLARE @phone as NVARCHAR(50);
DECLARE @PeoplePhoneCursor as CURSOR;
-- HERE IS WHERE WE SET THE CURSOR TO BE FAST_FORWARD
SET @PeoplePhoneCursor = CURSOR FAST_FORWARD FOR
SELECT TOP 10 FirstName, MiddleName, LastName, PhoneNumber
FROM person.Person p
INNER JOIN person.personphone pp on p.BusinessEntityID = pp.BusinessEntityID;
OPEN @PeoplePhoneCursor;
FETCH NEXT FROM @PeoplePhoneCursor INTO @firstName, @middleName, @lastName, @phone;
WHILE @@FETCH_STATUS = 0
BEGIN
PRINT ISNULL(@firstName, '') + ' ' +
ISNULL(@middleName, '') + ' ' +
ISNULL(@lastName, '') +
' Phone: ' + ISNULL(@phone, '') ;
FETCH NEXT FROM @PeoplePhoneCursor INTO @firstName, @middleName, @lastName, @phone;
END
CLOSE @PeoplePhoneCursor;
DEALLOCATE @PeoplePhoneCursor;The FORWARD_ONLY CURSOR takes 4 times the time as the FAST FORWARD CURSOR, and the number continues to widen as the number of times the cursor loops is executed.
FAST FORWARD CURSORS are usually the fastest option with SQL Server. There may be cases where another option may work better, but the FAST FORWARD CURSOR is a good place to start if you must use a CURSOR.
The best practice is to avoid cursor but sometime they are inevitable. The alternatives could be temp tables, while loops etc.